Trong SEO, Robots.txt là một trong những bước đầu tiên bạn cần thực hiện. Việc thực hiện không đúng cấu hình hoặc gặp sự cố đều có thể dẫn đến những tác động tiêu cực và thứ hạng website của bạn. Tìm hiểu Robot txt là gì giúp người làm SEO làm bạn với Google một cách tốt nhất.

Robot txt là gì?
Robots txt là tệp tin dưới dạng text nằm trong thư mục gốc của một website với mục đích cung cấp hướng dẫn cho các công cụ tìm kiếm thu thập thông tin, truy cập, index nội dung và cung cấp những nội dung đó cho người dùng.
Tệp tin này là một phần của REP (Robots Exclusion Protocol) chứa một nhóm các tiêu chuẩn website quy định các robot web hoặc robot công cụ tìm kiếm. REP cũng bao gồm các lệnh như meta robots, page-subdirectory, site-wide instructions giúp hướng dẫn các công cụ tìm kiếm xử lý các liên kết.
Tạo file Robots.txt trên wordpress giúp quản trị website chủ động hơn trong việc cho phép các bot của công cụ tìm kiếm index một phần nào đó trong website của chính mình. Đây đây bạn đã hiểu robot txt là gì rồi phải không nào? Nếu như muốn mở rộng kiến thức đọc thêm.
Vì sao nên sử dụng Robots.txt?
Sử dụng Robots.txt trên wordpress giúp bạn kiểm soát được việc truy cập của các bot đến các khu vực nhất định trên trang. Đồng thời, nó giúp ngăn chặn nội dung trùng lặp xuất hiện trên một website; giữ một số phần của website ở chế độ riêng tư; giữ các trang kết quả tìm kiếm nội bộ không hiển thị SERP, chỉ định vị trí sitemap; ngăn chặn các công cụ tìm kiếm index một số tệp nhất định trên website; ngăn chặn việc máy chủ bị quá tải khi các trình dữ liệu tải nhiều nội dung cùng một lúc.

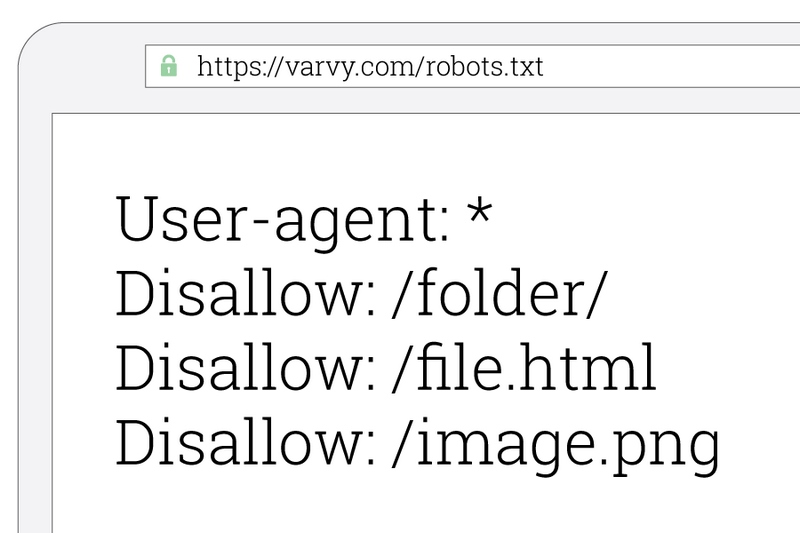
Cú pháp phổ biến của tệp Robots.txt
User-agent: là tên của các trình thu thập dữ liệu web.
Disallow: sử dụng để thông báo cho các user agent không thu thập các dữ liệu URL cụ thể nào.
Allow (chỉ áp dụng cho Googlebot): thông báo có thể truy cập vào 1 trang hoặc 1 thư mục con mặc dù nó có thể không được phép truy cập.
Crawl-delay: thông báo cho các web crawler phải đợi trước khi tải hoặc thu thập nội dung trang.
Sitemap: cung cấp các vị trí bất kỳ XML sitemap được liên kết với URL.
Robots.txt hoạt động như thế nào?
Có 2 nhiệm vụ chính: Crawl dữ liệu trên trang web để khám phá nội dung và Index nội dung để đáp ứng yêu cầu tìm kiếm của người dùng.
Để crawl được dữ liệu, các công cụ tìm kiếm sẽ đi theo các liên kết từ trang này đến trang khác rồi thu thập dữ liệu từ rất rất nhiều trang web khác.
Sau khi đến một trang web, trước khi crawl, các con bot của công tụ tìm kiếm sẽ tìm các file Robots.txt. Nếu tìm thấy 1 tệp robots.txt, nó sẽ đọc tệp đó đầu tiên.
Robots.txt chứa các thông tin về công cụ tìm kiếm nên thu thập dữ liệu của web. Tại đây, bot sẽ được hướng dẫn nhiều thông tin hơn.
Nếu Robots.txt không có chỉ thị cho các user-agent hoặc nếu bạn không tạo file robots.txt cho website thì các con bots sẽ tiến hành thu thập các thông tin khác trên web. Khi hiểu được robot txt là gì thì việc biết cách nó hoạt động sẽ giúp bạn phát triển website tốt hơn.
Cách tạo Robots.txt
Bạn chỉ cần soạn thảo văn bản có thể trên notepad và truy cập các tệp của trang web qua FTP hoặc bảng điều khiển quản lý hosting.
Nhưng, trước khi tạo, bạn cần kiểm tra xem nó đã có chưa bằng cách mở một cửa sổ trình duyệt mới và truy cập đến tenmien/robots.txt. Nếu thấy:
User-agent: *
Allow: /
Có nghĩa là bạn đã có Robots.txt rồi và có thể chỉnh sửa tệp hiện tại thay vì tạo mới.
Chỉnh sửa bằng cách sử dụng FTP và kết nối với thư mục gốc của trang web vì Robots.txt luôn nằm trong thư mục gốc. Tải tập tin về máy và mở nó dưới dạng soạn thảo văn bản. Thực hiện các thay đổi cần thiết và tải tệp lên máy chủ của bạn.
Ví dụ: User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml
Đây là cách cho phép tất cả các chương trình truy cập trang web của bạn mà không chặn bất kỳ thư mục hay URL nào. Nó cũng xác định vị trí sơ đồ web để làm cho công cụ tìm kiếm dễ dàng thấy nó hơn.
Hạn chế của robots.txt
Trước khi tạo hoặc chỉnh sửa tệp tin robots.txt, bạn nên biết các giới hạn của phương pháp chặn URL này. Đôi khi, chúng ta có thể muốn xem xét các cơ chế khác để đảm bảo rằng các URL của bạn khó có thể tìm thấy trên web. Cụ thể như là lệnh Robots.txt có thể không được tất cả các công cụ tìm kiếm hỗ trợ, trình thu thập khác nhau phân tích cú pháp khác nhau, Google đôi khi có thể lập chỉ mục một trang bị chặn bởi robots.txt nếu trang đó được liên kết từ những trang web khác.
Với những thông tin hữu ích trên đây, chúng tôi đã lần lượt lý giải thuật ngữ về Robots.txt, tầm quan trọng, làm thế nào để tối ưu nó hợp ý với Google… Nếu đang làm việc trong lĩnh Marketing mà đặc biệt là chuyên ngành SEO, tất cả những vấn đề về file Robots.txt là rất quan trọng, giúp bạn thuận lợi và đạt được những hiệu quả hơn trong công việc.
Robots.txt rất quan trọng đối với một website và bạn cần thực hiện nó đầu tiên khi tạo web. Với những thông tin trên đây, hy vọng sẽ hữu ích và đưa website của bạn tiếp cận được với nhiều người dùng hơn.